Creating a Simple ETL Pipeline With Apache Spark
Transforming raw data into a star schema with simple (py)spark code
Introduction
Apache Spark is a famous data processing tool, and if you are familiar with the data engineering/science world, you have probably already heard about it.
As an aspirant for data-related jobs, spark has been my study topic for an extended period. I tested its main functionalities, built and rebuilt the quickstart guide, and read some chapters from the book “Spark: The Definitive Guide: Big Data Processing Made Simple”. I also read a few articles online explaining when spark is good, when spark is bad, who uses spark for what, and so on.
So, the next logical step is to get my hands dirty.
With all that said, this post will explain a simple project that I’ve built using spark as my main data processing tool.
Setting up the environment
What you need to run this project:
- Python 3.6+, with the libraries:
requests -> to download the files
psycopg2 -> to connect to Postgres and execute SQL statements
pyspark -> connect to Apache Spark - Apache Spark installed in your local machine with the connection Jars from Postgres configured
- Docker and Docker Compose: Used to create a Postgres and a Metabase (BI tool) instance.
- Postgres container config:
POSTGRES_USER = “censo”
POSTGRES_PASSWORD = “123”
POSTGRES_DB = “censo_escolar”
All the code is available in this GitHub repository.
Implementation
The idea of this project will be to extract raw data from the Brazilian Government’s Open Data Website so we can build some analysis and dashboards. (This will be our excuse to use spark)
We’ll be working with data from the Brazilian National Basic Education Census from 2010–2020, which yearly collects (a lot of) information about all the Brazillian basic education schools from many perspectives, such as structural, ethnical, geographical, economic, etc.
This data can be downloaded as CSV files in the link.
In order to make the data ready to answer our questions (in the dashboard), we need to structure it in a Star Schema on a SQL Database, and that is when apache spark comes in.

The Star Schema is a way to model our data in the DB in order to improve aggregating query’s execution time. It’s used when we’re more interested in answering aggregating questions (“How many students frequented the kindergarten in 2020”) than reducing redudancy and disk space usage (normalization) .
It will be the component responsible for transforming the plain CSV files into the Star Schema tables. The code is written in python and uses the PySpark library (considering that apache spark is already installed on your local machine).
The image below explains how the pipeline is structured:

It has the following steps…
- Extract the data from the source, which in this case will be the internet
- Convert the CSV files into parquet. This aims to speed up the full process since parquet files are way faster to read than CSV
- Transform the data in the Star Schema format.
- Create and populate the Dimensions and Facts Tables in a Postgres instance.
… that are explored in the following sections
Extracting the data
This is a very simple step, with only a few code lines.
It downloads the files from the Brazilian Open Data portal and stores the CSV files in the folder ./data. The code is written in python but is mainly invoking Linux bash commands through the os library.
After the execution, the./data directory should end with the following files:
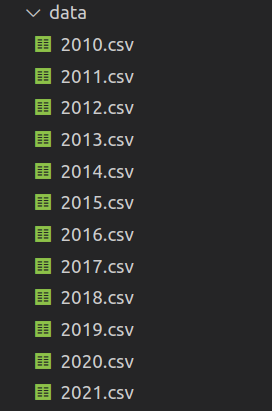
Before continuing, I would like to emphasize some aspects of this data.
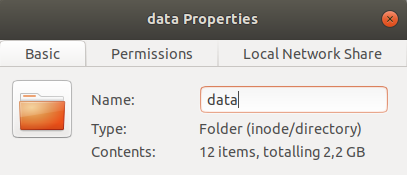
Each CSV file has 370 columns, taking approximately 180Mb of disk space, totaling ~2.2 Gb of data. Trying open all this data with Pandas is very slow (and ofter crashed my poor VM ), so we need another approach.
And that’s one of the advantages of using spark: its transformations are lazily evaluated. This means that spark will not load the data into memory and then perform operations on it (like Pandas), but instead, it will first wait for the definition of the queries and then fetch the data from the disk. This gives the ability to optimize the query and load in memory just the needed for answering the questions.
Transforming CSV into Parquet
Even with the Spark optimizations, working with CSV files is still slow. To overcome this, we need to transform our data into parquet files, that are way smaller (compressed) and structured to answer our analytical questions faster. This is will be our first use of spark.
The first step is to instantiate the spark session:
The spark object stores our interface with Spark in python.
Next, the CSV data is ‘loaded’ in spark.
As said before, the spark doesn’t load any data in memory until an action is called, so I think that the better way to describe this step is “the creation of a reference to a data source”.
If you already worked with CSV files, the options header, delimiter, and encoding should be familiar, they’re metadata about how the file is structured. The option inferSchema says to Spark that we will not provide the table’s schema (columns names + types) then it should try to interpret the contents to extract this information.
Finally, we say to Spark to save the data as a parquet file. This is when it will interact with the data.
The final file is ~5x smaller and the performance improvements on the queries can be easily felt empirically.
Finally, the parquet file can be ‘loaded’ in spark so we can start working on the Star Schema’s construction.
Creating the dimensions tables
The first step to transforming our data to a star schema is to create and populate the dimensions table.
And here goes a small recap of these tables: they represent aspects of the observations that we want to explain, and are usually low cardinality static groups (small groups unlike to change). For example, in the question “What is the population of each South America country?”, the population is our fact/metric, and the group of South American countries is a dimension.
As the fact table references the dimensions tables, they need to be defined and populated first.
These are the steps to be done to create a dimension table:
- Specify which columns from the source will compose the dimension
(casting for specific types if needed) - Extract the unique values from the columns
- Add a unique id for each entry. This id will be the table’s primary key.
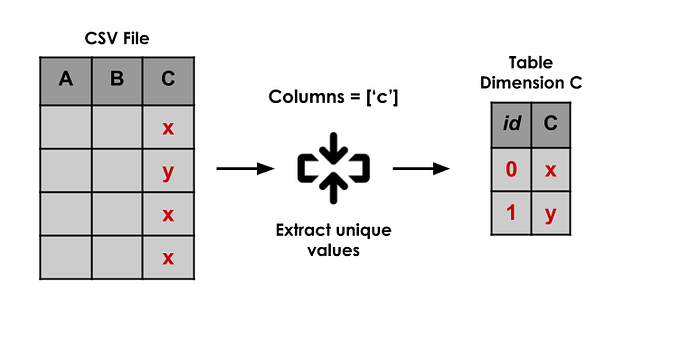
For example, if I want to create a dimension for the school’s location (CITY + STATE), this information is the set of columns: {‘NO_UF’, ‘SG_UF’, ‘CO_UF’, ‘NO_MUNICIPIO’, ‘CO_MUNICIPIO’}. The code will be something like this:
One very nice fact that I discovered while making this project is that when writing to a JDBC (Postgres in this case) with mode=“overwrite” the Spark will automatically create the table (deleting it, if it already exists), so no previous structure is needed in the database.
Unfortunately, there is no way (that I found) to also define the primary key with Spark, so we need to run a simple SQL script in Postgres. This is done with the psycopg library.
This is the basic logic, all that rest is to generalize this idea for other columns. The code below shows how I made this generalization (and I hope it’s not confusing).
For each table, a dictionary is defined with the following structure:
{
“dimension table name”:
“fields": [ {"field":"column", "type":"field type"}, ... ]
}specifying the fields (with their types) that compose the dimension
This structure allows building all the dimensions in a simple for loop.
The code is not one of the most beautiful things in the world, but I think that it has a good balance between simplicity and generalization.
It takes no more than 2mins to create all the dimensions, see the logs below.
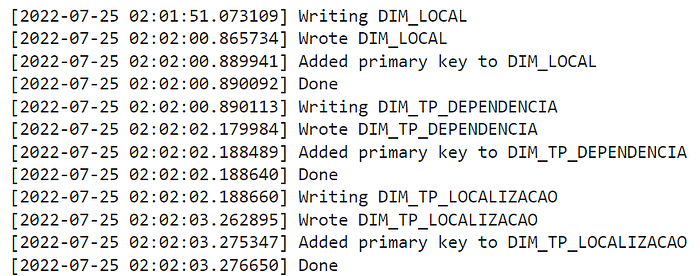
The tables in the database:
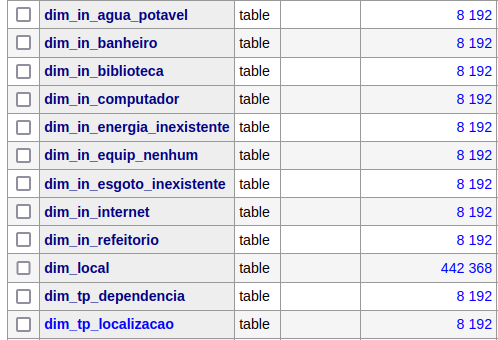
With that, we’re halfway done, and the next step is to create the facts table.
Creating the facts table
The facts table is the table in the Star Schema’s center, and it's composed of a group of metrics (for example, the total number of products sold) with their respective attributes (the dimensions, referenced via their primary key).
Because of this, its definition is a lit bit more complex, with the following steps:
- Specify which columns from the source will compose the facts
(casting for specific types if needed) - Add an id column for each dimension (referencing foreign key)
- Referencing dimension attributes through their ids in the dimension tables
After analyzing the data, I choose the following columns to compose my facts table:
Following the same logic used before (for the dimensions tables), two configuration dictionaries are used to describe the table, one containing the structure of the facts table’s columns (Name + type), and the other containing information about the dimensions to make possible retrieve the correct Id from the dimensions table.
This decision of creating a configuration structure before writing any code itself is a simple strategy that I use to make the code more generic, so I can tweak parameters more easily and make use of it in other projects.
With this information in hand, we can build the SQL command that will create our facts table.
Besides looking complicated, the script just creates a table with the fact’s columns specified and an id column referencing each dimension. The script is executed with the psycopg library, just as before.
With the fact table finally created, we can clap our hands and say: our star schema is ready.
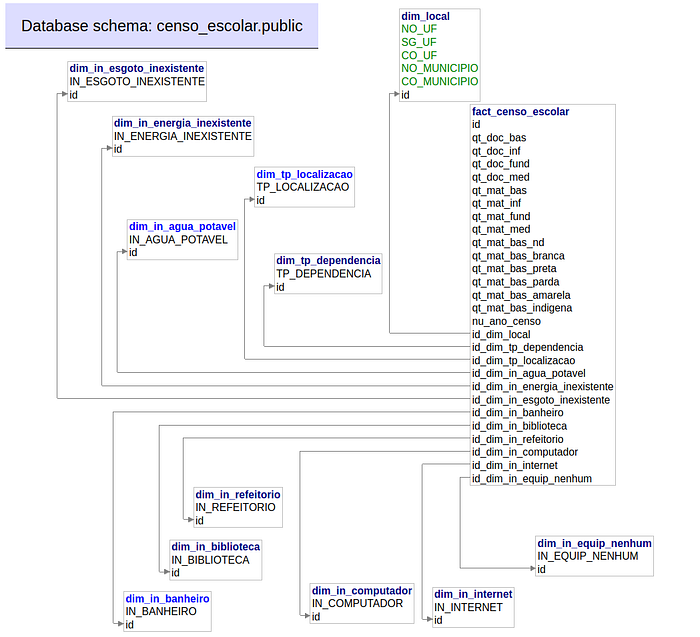
Yes, I know that this doesn’t look like a Star.
There is no data there, so let’s go back to the code to populate it.
Again, the first thing to do is to select the columns that gonna be used in the facts table (Facts + Dimensions).
Then, a join is performed with each dimension table to bring their ids. After that, the columns used in the join are dropped, to keep just the id reference.
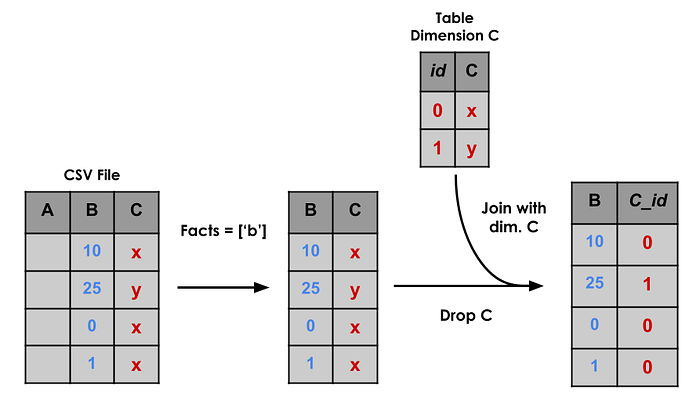
It's nice to remember: Up to this moment, spark still has done no work with the data, it just wrote a plan on how the query above should be executed.
So, all that rest is to save this data in Postgres.
Note that the parameter mode is set to “append”, i.e. the spark will write new entries to the table, and not create it from scratch and drop the data that was there before.
This behavior is essential for a fact table since it is supposed to be a “append only” structure, where historical data is maintained for further analysis.
After a few minutes of execution, our Postgres database is ready.
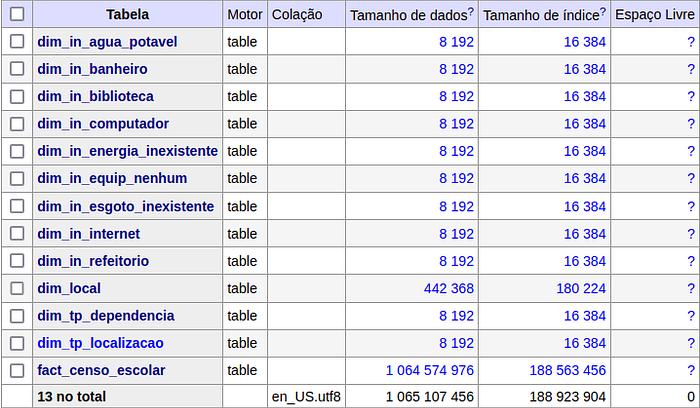
Unfortunately, I cannot print the entire facts table here to prove that the code works, as it has ~3 mi entries, so you’ll need to trust me.
The dashboard
As I said at the beginning of this post, the Star Schema is a way to model our data in a SQL database to speed up aggregating queries, which is especially useful for large BI applications.
To avoid making this post bigger, let me show briefly some potential dashboards that can be made using this structure.
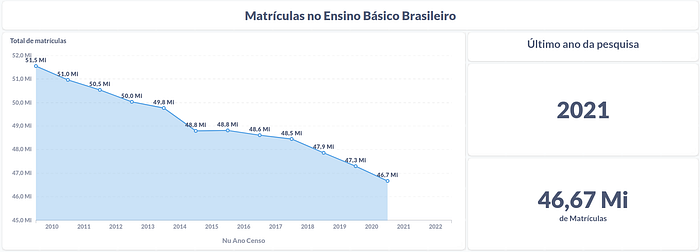
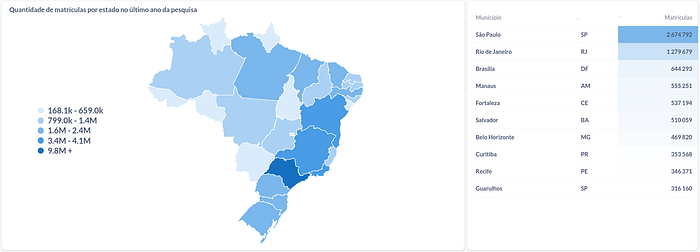
Conclusion
When learning a new tool/concept I always find it helpful to create a simple project using it, so I can better fix the knowledge in my head (and that’s where many of these posts' ideas came from).
I personally like to work with real datasets of subjects that I like, so that I can give more meaning to the work and think about the real advantages of the built applications. Besides that, I also chose this dataset because it is not trivial, it has 370 columns and ~3 mi rows. I know that this is not even closer to being BIG DATA, but as I said, this is meant to be a simple project.
With this data, we explored a few functionalities of Apache Spark to help us create a Star Schema. I found that, even with the complexity intrinsic to a Big Data processing tool, the use of Apache Spark is quite simple, especially if you are someone with a Pandas background, because is quite easy to note similarities and migrate knowledge.
Finally, our data is ready in the database, and we can make use of it.
I hope this post helped you somehow, I am not an expert in any of the subjects discussed, and I strongly recommend further reading (see some references below).
Thank you for reading! ;)
References
[1] What is the Parquet File Format and Why You Should Use It.
[2] On explaining technical stuff in a non-technical way — (Py)Spark.
[3] Adding sequential IDs to a Spark Dataframe — How to do it and is it a good idea?
[4] PySpark Read and Write Parquet File. sparkbyexamples.com
[5] Star and Snowflake Schema in Data Warehouse with Model Examples. Guru99
[6]Data Warehouse Concepts — Guru99
[7] Chambers, Bill, and Matei Zaharia. Spark: The definitive guide: Big data processing made simple. “ O’Reilly Media, Inc.”, 2018.
All the code is available in this GitHub repository.
Some observations:
A. The school-related translations are not perfectly accurate, since the Brazillian system is not equal to the US/UK systems.
B. I preferred to not translate the Skin color/race categories, also because they might not accurately reflect the reality of other countries.
